s =
ss =
Jakość usług (QoS)
Wraz z popularyzacją Internetu, który mógł tworzyć każdy, niezbędne okazało się określenie usług jakie taka globalna sieć powinna udostępniać oraz jakie parametry należy tym usługom zagwarantować by były użyteczne. Usystematyzowanie tych parametrów nosi miano jakości usług (Quality of Service). Pierwszy opis jakości usług został dokonany w 1993 roku przez Scotta Schenkera, Davida Clarcka i Lixie Zang [1]. Wprowadzili podział zapewniania usługi (service commitment) na kilku płaszczyznach. Po pierwsze, określać przydział można:
- ilościowo – dokładnie określić np. minimalne opóźnienie jakiego doświadczą pakiety podczas przesyłu,
- jakościowo/względnie – np. przydział będzie z pewną wagą w stosunku do innego, lub z wyższym priorytetem.
- pojedyńczego połączenia,
- wielu połączeń należących do danego użytkownika, sieci lub rodzaju usługi (usługi zbiorcze/intergrated services).
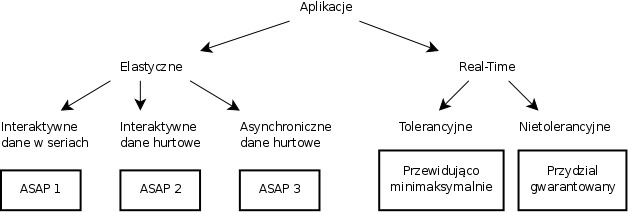
Wymagania dotyczące połączeń
Autorzy zwracają uwagę na to, że najważniejszym parametrem usługi jest opoźenienie, a konkretnie jego minimalna i maksymalna możliwa wartość. Wymogi jakie stawiają aplikacje tym parametrom klasyfikują je w sposób pokazany na rysunku. Nie jest to podział dokładny, a jedynie obrazujący rozwój algorytmów kolejkowania danych. ASAP (As Soon As Possible) to określenie wysyłania pakietów tak szybko jak to możliwe bez narażania innych usług na niespełnienie swoich warunków. Pakiety z tej kategorii wybierane są w kolejności określonej według ustalonego priorytetu (kolejno ASAP1, ASAP2, ASAP3). Przewidujący minimaksymalny algorytm to sposób dzielenia minimaksymalnie według potrzeb jakie zdaje się mieć aplikacja. Chodzi tu między innymi o usługi przekazujące strumień, które dostosowują ilość danych do prędkości połączenia. Przykładowe aplikacje według podziału:
- Real-Time – Usługi wymagające dostarczenia danych w określonym czasie, najcześciej natychmiastowo.
- Tolerancyjne – Strumienie audio/video dostosowujące ilość danych do predkości połączenia (np. VoIP)
- Nietolerancyjne – Wymagające stałej gwarantowanej dostępności zasobu, np. zdalne operacje chirurgiczne
- Elastyczne – Usługi których nagłe zmiany opóźnienia nie wpływają istotnie na funkcjonowanie; które zawsze maja coś do wysłania, lub zawsze czekają na dane
- Interaktywne, dane w seriach – Zdalna administracja (Telnet, SSH), zdalny pulpit (X, VNC)
- Interaktywne, dane hurtowo – Przesyłanie dużych danych bezpośrednio (FTP)
- Asynchroniczne, dane hurtowo – Przesyłanie danych bez natychmiastowego potwierdzenia (poczta elektroniczna)
Wymagania dotyczące usług zbiorczych
Podczas gdy dla pojedyńczego połączenia liczy się opóźnienie, to z punktu widzenia interfejsu sieciowego routera, który przepustowość swego łącza musi rozdzielić optymalnie, najważniejszą wartościa dotyczącą połączenia jest jego ogół przepustowości w danej jednostce czasu. Ogół czynności z tym związanych określa się mianem wspołdzielenia łącza (link-sharing). W zależności od typu przedmiotów współdzielących wyróżnia się współdzielenie na bazie:
- jednostek – Łącze dzielone jest pomiędzy użytkowników lub podsieci (np. organizacje które wykupiły dostęp do łącza);
- protokołów – Niektóre protokoły mogą mieć wiekszy priorytet od innych. W tej chwili rzadko stosuje się ten typ podziału, gdyż większosć sieci komputerowych bazuje jedynie na protokole TCP/IP;
- usług – Jedną grupę usług (np. interaktywnych) możemy faworyzować, by nie były zakłócane przez usługi o mniejszym znaczeniu (np. asynchroniczne).
Problem wymaga jasnego określenia zasad współdzielenia. Rozpatrzmy następujący przykład (tamże, s. 15 :) ): Firmy 1, 2, 3 mają udział w łączu odpowiednio $1/4$, $1/4$, $1/2$. Przypuśćmy, że przez godzinę firma 1 nie korzysta z łącza, a firmy 2 i 3 przesyłają dane mogące wykorzystać całość łącza. Czy te dwie firmy powinny być ograniczone tylko do swoich udziałów, czy też mogą użyć niewykorzystanego pasma firmy 1? Jeśli tak, to jak podzielić dodatkowe pasmo pomiędzy interesantów? Ponadto, jeśli przez kolejne 20 minut, wszystkie firmy będą w stanie wykorzystywać całość łącza, to czy należy brać pod uwage debet firmy 1 w średniej przepustowości powstały przez godzinę nieaktywności, czy też dzielić sztywno według pierwotnych udziałów? Podczas gdy podział dodatkowego pasma można podzielić proporcjonalnie do udziałów, to przedział czasu w którym należy obliczać średnią przepustowość jest trudny do określenia. Zbyt duży czas, może zatrzymać przesył danych firm 2 i 3 póki debet przepustowości firmy 1 nie wyrówna się. Może to mieć poważny, negatywny wpływ na wymagania usług firm 2 i 3 dotyczące maksymalnego opóźnienia.
Wyidealizowany model współdzielenia łącza zaproponowany przez Demersa, Keshava i Schenkera [2] mówi, że w każdej chwili dostępne pasmo jest rozdzielone pomiędzy aktywnymi jednostkami proporcjonalnie do swych udziałów. Oznaczmy $\mu$ jako przepustowość łącza. Przydzielmy każdemu połączeniu $i$ jego włąsną wirtualną kolejkę do której lądują pakiety przesyłanie przez to połączenie. Każde takie połączenie charakteryzują następujące wartości:
- $s_i$ – zdefiniowany udział łącza (ułamek łącza)
- $c_i(t)$ – ilość bitów które przypłynęły do kolejki $i$ w chwili $t$
- $b_i(t)$ – ilość bitów znajdujących się w kolejce $i$ w chwili $t$
Wartość $b'_i(t)$ określa z jaką prędkością może przesyłać dane połączenie $i$. Jeśli pochodna jest ciągła, otrzymujemy podział idealny, i choć niemożliwy do uzyskania w rzeczywistości to stanowiący dobre kryterium większości algorytmów kolejkowania.
Przypisy- [^] Scott Schenker, David D. Clarck i Lixia Zang ,,A Scheduling Service Model and a Scheduling Architecture for an Integrated Services Packet Network'', ACM/IEEE Trans. on Networking, 1993
- [^] A. Demers, S. Keshav, S. Shenker ,,Analysis and Simulation of a Fair Queuing Algorithm'', ACM SIGCOMM'89, 1990

|
Content by Michał Pokrywka
is licensed under a Creative Commons BY-SA 3.0 Ostatnia znacząca zmiana: 2010-04-28 |