s =
ss =
Globalna synchronizacja
W sieciach opartych na protokole TCP/IP istnieje aspekt problemu przeciążenia zwany globalną synchronizacją. Związane jest to ze sposobem działania protokołu TCP/IP.
Protokół TCP/IP cechuje:
- Transmisja pozbawiona błędów (z punktu widzenia aplikacji wykorzystujących protokół)
- Uporządkowany przesył danych osiągany za pomocą zakodowanej w pakietach sekwencji, odpornej na wielokrotną fragmentację (Numerowane sa nie pakiety lecz pojedyńcze bajty)
- Odrzucanie zwielokrotnionych pakietów
- Retransmisja zgubionych pakietów
- Kontrola przepływu i zapobieganie przeciążeniom za pomocą koncepcji okna przesuwnego (ang. sliding window)
Dwie ostatnie cechy odgrywają tutaj kluczową rolę. Sposób w jaki możnaby wyobraźić sobie proste przesyłanie danych wymagających potwierdzenia (ACK) jest nieoptymalny z uwagi na to, że zarówno odbiorca jak i nadawca przez większość czasu czekaja (patrz rys. A).
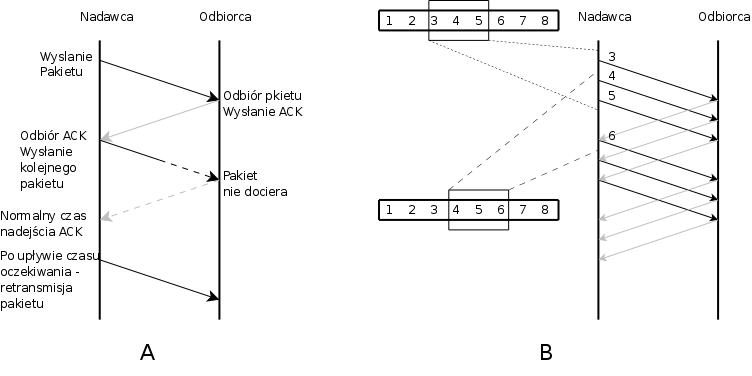
Zastosowanie zasady okna przesuwnego pozwala na lepsze wykorzystanie pasma transmisji przez możliwość wysłania większej ilości pakietów zanim poprzednie zostaną potwierdzone. Okno jest sukcesywnie powiększane do momentu kiedy wszystkie pakiety są potwierdzane. Pozwala to wykorzystywać optymalnie dostępne pasmo. Jeśli jednak potwierdzenia niedochodzą, okno zmniejsza się by dostosować się do warunków połączenia. Aby znaleźć odpowiednią prędkość, następuje powolne powiększanie okna (tzw. slow-start). Odrzucanie pakietów jest spowodowane znajczęściej zapełnieniem bufora w urządzeniu odbierającym (tzw. tail drop – najprostszy algorytm do zapobiegania przepełnieniu bufora, polega na odrzucaniu wszystkich nadchodzących pakietów dopóki bufor jest pełny), więc dotyczy to wszystkich danych z każdego połączenia. Efekt ten następuje zatem równocześnie we wszystkich połączeniach. Odstępy pomiędzy powiekszaniem okien tych połączeń a zmniejszaniem w wyniku przeciążenia synchronizują się, powodując, że kolejne przeciążenia są coraz większe. Stan ten nazwano globalną synchronizacją (ang. global synchronization).
Problem ten może wystąpić nagle w stabilnie działającej sieci, w której jakiemuś urządzeniu przekazującemu zabraknie miejsca w buforze. Kiedy jedno z połączeń wygeneruje chwilowy nadmiarowy przypływ danych, bufor się przepełni i nastąpi zmniejszenie okien dla pozostałych ustabilizowanych sesji co zapoczątkuje proces globalnej synchronizacji. Rozwiązaniem jest utrzymywanie podatnych buforów na niskim poziomie zapełnienia, co zmniejsza przepustowość (ale poprawia interaktywność – dużo algorytmów kolejkowania danych bazuje więc na tym podejściu, np. Random Early Detection).

|
Content by Michał Pokrywka
is licensed under a Creative Commons BY-SA 3.0 Ostatnia znacząca zmiana: 2010-04-28 |