s =
ss =
Oryginalne SFQ
Jedną z prostych a równocześnie ciekawych i powszechnie stosowanych implementacji algorytmu sprawiedliwego kolejkowania jest SFQ Stochastic Fair Queuing).
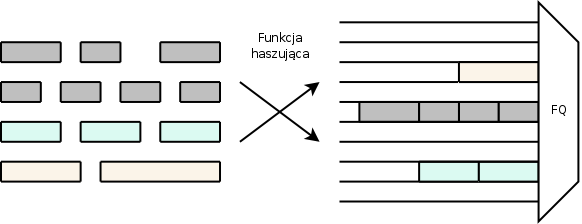 |
Algorytm ten został zasugerowany przez Paula McKenney'ego juz w 1990 roku[1], jako rozwiązanie problemów implementacyjnych FQ. Bazuje on nie na pojedyńczych połączeniach, ale na parach źródło-przeznaczenie według nagłówka IP i na tej podstawie przydziela pakiety do odpowiednich kolejek. Przydział ten odbywa się za pomocą funkcji haszującej, ilość kolejek jest więc stała a pakiety z różnych par mogą trafić do tej samej kolejki. To sprawia ze SFQ oddala się jeszcze bardziej od ideału sprawiedliwości wyznaczonego przez Demersa, Keshava i Shenkera. Jeśli dwa kolidujące ze sobą pary trafią do jednej kolejki algorytm praktycznie przestaje działać. Dlatego SFQ co jakiś czas (na przykłąd kilka sekund) zmienia funkcje haszującą, kolizje mogą się więc pojawiać tylko przelotnie. McKenney wskazuje, że aby osiągnąć zadowalające wyniki (zbliżone do FQ i z kolizjami zdarzającymi się sporadycznie) potrzebna jest duża ilość zdefiniowanych kolejek – okolo 5 do 10 razy więcej niż przewidywana ilość aktywnych par.
Ostatecznie algorytm okazał się dużo szybszy od zwykłej implementacji FQ, a przewaga ta rośnie wraz ze wzrostem ruchu sieciowego przepływającego przez urządzenie. Należy tutaj wyjaśnić, że algorytm sfq zaimplementowany w Linuksie 2.2 przez Alexey'a Kuznietsova, bazuje na pracach McKenney'ego, jednak odbiega od oryginalnej koncepcji sprawiedliwego kolejkowania Johna Nagle'a oraz modelu FQ na rzecz Deficytowego Algorytmu Karuzelowego.
Implementacja i zastosowanie (w linuksowym sfq)
Przypisy

|
Content by Michał Pokrywka
is licensed under a Creative Commons BY-SA 3.0 Ostatnia znacząca zmiana: 2010-04-28 |